
散列函数
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
如今,散列算法也被用来加密存在数据库中的密码(password)字符串,由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值)的性质,因此可有效的保护密码。
散列函数的性质
所有散列函数都有如下一个基本特性:如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。这个特性是散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。但另一方面,散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同,这种情况称为“散列碰撞(collision)”,这通常是两个不同长度的输入值,刻意计算出相同的输出值。输入一些数据计算出散列值,然后部分改变输入值,一个具有强混淆特性的散列函数会产生一个完全不同的散列值。
典型的散列函数都有非常大的定义域,比如SHA-2最高接受(264-1)/8长度的字节字符串。同时散列函数一定有着有限的值域,比如固定长度的比特串。在某些情况下,散列函数可以设计成具有相同大小的定义域和值域间的单射。在密码学中,散列函数必须具有不可逆性。
散列函数的应用
由于散列函数的应用的多样性,它们经常是专为某一应用而设计的。例如,加密散列函数假设存在一个要找到具有相同散列值的原始输入的敌人。一个设计优秀的加密散列函数是一个“单向”操作:对于给定的散列值,没有实用的方法可以计算出一个原始输入,也就是说很难伪造。为加密散列为目的设计的函数,如SHA-2,被广泛的用作检验散列函数。这样软件下载的时候,就会对照验证代码之后才下载正确的文件部分。此代码不会因为环境因素的变化,如机器配置或者IP地址的改变而有变动。以保证源文件的安全性。
错误监测和修复函数主要用于辨别数据被随机的过程所扰乱的事例。当散列函数被用于校验和的时候,可以用相对较短(但不能短于某个安全参数, 通常不能短于160位)的散列值来验证任意长度的数据是否被更改过。
保护资料
散列值可用于唯一地识别机密信息。这需要散列函数是抗碰撞(collision-resistant)的,意味着很难找到产生相同散列值的资料。散列函数分类为密码散列函数和可证明的安全散列函数。第二类中的函数最安全,但对于大多数实际目的而言也太慢。透过生成非常大的散列值来部分地实现抗碰撞。例如,SHA-256是最广泛使用的密码散列函数之一,它生成256比特值的散列值。
确保传递真实的信息
消息或数据的接受者确认消息是否被篡改的性质叫数据的真实性,也称为完整性。发信人通过将原消息和散列值一起发送,可以保证真实性。
散列表
散列表是散列函数的一个主要应用,使用散列表能够快速的按照关键字查找数据记录。(注意:关键字不是像在加密中所使用的那样是秘密的,但它们都是用来“解锁”或者访问数据的。)例如,在英语字典中的关键字是英文单词,和它们相关的记录包含这些单词的定义。在这种情况下,散列函数必须把按照字母顺序排列的字符串映射到为散列表的内部数组所创建的索引上。
散列表散列函数的几乎不可能/不切实际的理想是把每个关键字映射到唯一的索引上(参考完美散列),因为这样能够保证直接访问表中的每一个数据。
一个好的散列函数(包括大多数加密散列函数)具有均匀的真正随机输出,因而平均只需要一两次探测(依赖于装填因子)就能找到目标。同样重要的是,随机散列函数不太会出现非常高的冲突率。但是,少量的可以估计的冲突在实际状况下是不可避免的(参考生日悖论或鸽洞原理)。
在很多情况下,heuristic散列函数所产生的冲突比随机散列函数少的多。Heuristic函数利用了相似关键字的相似性。例如,可以设计一个heuristic函数使得像FILE0000.CHK, FILE0001.CHK, FILE0002.CHK,等等这样的文件名映射到表的连续指针上,也就是说这样的序列不会发生冲突。相比之下,对于一组好的关键字性能出色的随机散列函数,对于一组坏的关键字经常性能很差,这种坏的关键字会自然产生而不仅仅在攻击中才出现。性能不佳的散列函数表意味着查找操作会退化为费时的线性搜索。
错误校正
使用一个散列函数可以很直观的检测出数据在传输时发生的错误。在数据的发送方,对将要发送的数据应用散列函数,并将计算的结果同原始数据一同发送。在数据的接收方,同样的散列函数被再一次应用到接收到的数据上,如果两次散列函数计算出来的结果不一致,那么就说明数据在传输的过程中某些地方有错误了。这就叫做冗余校验。
校正错误时,至少会对可能出现的扰动大致假定一个分布模式。对于一个信息串的微扰可以被分为两类,大的(不可能的)错误和小的(可能的)错误。我们对于第二类错误重新定义如下,假如给定H(x)和x+s,那么只要s足够小,我们就能有效的计算出x。那样的散列函数被称作错误校正编码。这些错误校正编码有两个重要的分类:循环冗余校验和里德-所罗门码。
语音识别
对于像从一个已知列表中匹配一个MP3文件这样的应用,一种可能的方案是使用传统的散列函数——例如MD5,但是这种方案会对时间平移、CD读取错误、不同的音频压缩算法或者音量调整的实现机制等情况非常敏感。使用一些类似于MD5的方法有利于迅速找到那些严格相同(从音频文件的二进制数据来看)的音频文件,但是要找到全部相同(从音频文件的内容来看)的音频文件就需要使用其他更高级的算法了。
那些并不紧随IT工业潮流的人往往能反其道而行之,对于那些微小差异足够健壮的散列函数确实存在。现存的绝大多数散列算法都是不够健壮的,但是有少数散列算法能够达到辨别从嘈杂房间里的扬声器里播放出来的音乐的健壮性。有一个实际的例子是Shazam (页面存档备份,存于互联网档案馆) 服务。用户可以用手机打开其app,并将话筒靠近用于播放音乐的扬声器。该项服务会分析正在播放的音乐,并将它于存储在数据库中的已知的散列值进行比较。用户就能够收到被识别的音乐的曲名。
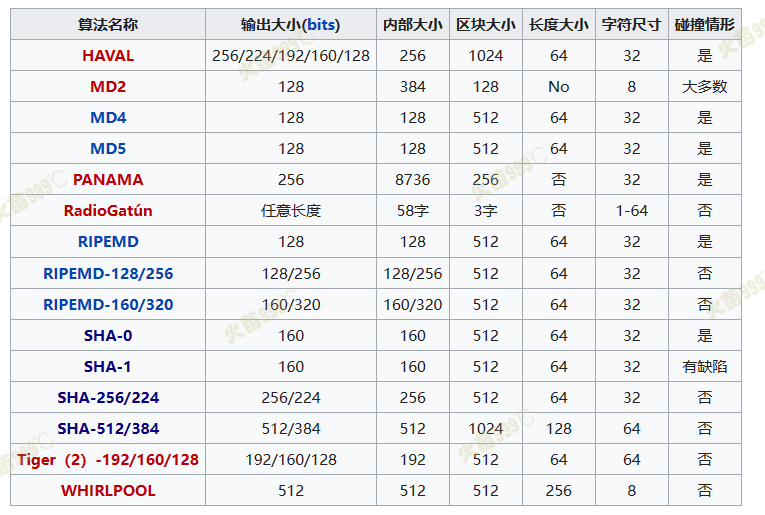
目前常见的散列算法
Rabin-Karp字符串搜索算法
Rabin-Karp字符串搜索算法是一个相对快速的字符串搜索算法,它所需要的平均搜索时间是O(n)。这个算法是创建在使用散列来比较字符串的基础上的。
原文地址:
https://zh.wikipedia.org/wiki/%E6%95%A3%E5%88%97%E5%87%BD%E6%95%B8
在知识共享 署名-相同方式共享 3.0协议之条款下提供



